Студентам > Рефераты > Звуковые карты и Компрессия звука
Звуковые карты и Компрессия звукаСтраница: 8/12
Итак, приступим к разбору
полетов, а точнее шумов. Сюрприз номер один - результаты интегрированной в
материнскую плату YMF724. А, точнее 16 бит кодека от TriTech, разведенного без
каких либо буферных элементов. Это практически запредельные результаты для 16
бит кодеков подобного класса. Фактически, копеечное аудио в материнской плате
умудрилось побить MX300 по качеству воспроизведения. Сюрприз номер два - сильно
выраженные зависимости отношения сигнал шум от частоты квантования как у MX300
так и у Live!. Природа этого явления проста - кодеки обоих карт работают на фиксированных
частотах квантования, а цифровые данные динамически перевыбираются для
приведения к этой заданной частоте. Но подобное преобразование неизбежно вносит
собственный вклад в помехи. Причем, судя по результатам, кодек Live! работает
на частоте 48000 а кодек Vortex2 наоборот, на частоте 44100. В документации на
чип говорилось о 48000 но, вероятно, инженеры из Diamond Multimedia сочли
необходимым установить фиксированную частоту равной обще принятому стандарту на
цифровой звук, дабы повысить качество воспроизведения в большинстве программ.
Итак, можно рекомендовать владельцам Live! настраивать свои программы на 48000,
а владельцем MX300 на 44100. Еще один сюрприз - десяти полосный цифровой
эквалайзер в Vortex2. По заявлениям Aureal имеющий отношение сигнал шум порядка
96 Дб. На практике все оказалось гораздо хуже - в случае отсутствия сигнала
эквалайзер действительно не вносит дополнительных шумов, что вполне логично,
учитывая его цифровую природу. Зато в нормальном режиме шумы абсолютно
непереносимы, выдвинутые в максимальные позиции движки способны ухудшить
отношение сигнал шум на добрых 15-20 Дб, что абсолютно не приемлемо. Приговор
прост - отключить его раз и навсегда, и пользоваться внешним усилителем с
эквалайзером.
При работе с Live! также были
замечены несколько странностей. Периодически (несколько раз в секунду)
появляется кратковременное постоянное смещение порядка 10Дб, причем это
происходит только при частоте квантования 44100. Вероятно, в это время DSP
переходит границу внутреннего буфера, с помощью которого выполняется расчет
эффектов или перевыборка частот, причем реализован этот переход некорректно.
Отключение всех эффектов не спасает от этой помехи, зато переход на частоту
48000 способен от нее избавить. Подобная же помеха наблюдается во время
регулировки громкости или примерно через треть секунды, после прекращения
какого-либо сигнала вне зависимости от частоты квантования. Еще одна странность
Live! - непомерное задирание высоких частот, при установленном в настройках
режиме вывода на наушники. При установке дешевых пищалок этот подход
оправдывает себя, т.к. способен несколько подправить их ущербную АЧХ, но в
случае мало-мальски нормальных наушников звук становится отвратительным, и даже
крайнее положение регуляторов тембра не спасает ваши уши. Кстати, эти
регуляторы в Live! сделаны на славу, они практически не вносят шумов, хотя,
есть подозрение на их цифровую природу.
Последнее замечание - о
микшировании сигналов. Если в MX300 и 6BTA2 эти функции полностью возложены на
кодеки (аналоговое микширование), то в Live! микширование выполняется цифровым
образом везде, где это только возможно. Поэтому при записи с внутреннего
микшера параметры определялись только шумами перевыборки, а в случае частоты
квантования 48000 шумы практически отсутствовали (т.е. превышали -96 Дб).
Загрузка
процессора и прочие цифры
Для всех карт использовались
последние из доступных на данный момент официальных драйверов (т.е. релизы).
Для сравнения приведены данные на карту Ensoniq Audio PCI (чип ES1370), у
которой отсутствует аппаратное ускорение DirectSound.
|
Параметр
|
MX300
|
Live!
|
6BTA2
|
ES1370
|
|
DirectSound каналов аппаратно
|
32
|
32
|
20
|
0
|
|
DirectSound3D каналов аппаратно
|
16
|
32
|
8
|
0
|
|
Загрузка CPU, DirectSound, 44100, 16 бит, 8 каналов
|
0.78
|
0
|
1.06
|
1.89
|
|
Загрузка CPU, DirectSound, 44100, 16 бит, 16 каналов
|
1.65
|
0
|
1.82
|
3.21
|
|
Загрузка CPU, DirectSound, 44100, 16 бит, 32 канала
|
4.58
|
0
|
3.62
|
5.97
|
|
Загрузка CPU, DirectSound3D, 44100, 16 бит, 8
каналов
|
6.85
|
1.8
|
8.09
|
13.8
|
|
Загрузка CPU, DirectSound3D, 44100, 16 бит, 16 каналов
|
7.90
|
2.44
|
20.4
|
25.1
|
|
Загрузка CPU, DirectSound3D, 44100, 16 бит, 32
канала
|
32.8
|
3.56
|
40.2
|
53.7
|
Какие же выводы можно сделать
глядя на эту колонку цифр. Live! несомненно чемпион, загрузка процессора
минимальна. Правда, в отличие от предыдущих драйверов, при воспроизведении
DirectSound3D потоков она стала возрастать линейно с числом голосов, хотя и не
превысила предыдущие значение (порядка 4% при любом количестве голосов). Это
легко объяснить, появлением HRTF функций, для которых необходима предварительная
обработка данных процессором отдельно для каждого потока, а не только установка
параметров реверберации всего помещения, как это было раньше. Именно благодаря
тому, что Live! является полноценным DSP с загружаемыми на борт программами,
загрузка процессора столь низка. Даже в случае применения HRTF функций, пусть и
не столь совершенных, как у MX300 (о качестве 3D звука будет сказано далее).
На втором месте MX300, причем
удивляет стабильный рост нагрузки при росте числа 2D потоков (попахивает
программной эмуляцией, особенно если сравнить результаты с практически
аналогичными у ES1370), вероятно все железные возможности были направлены на
обработку 3D потоков и их отражений. В случае 3D все хорошо до тех пор, пока
число каналов не превысит 16, аппаратно ускоряемые чипом. В новых драйверах
обещают поддержку 76 3D потоков, но не известно, окажется эта поддержка
полностью аппаратной или нет, и не ухудшит ли она качество 3D звука. Причем OEM
версия новых драйверов 2030 уже доступна в сети на сайте Aureal. В этих
драйверах реализована поддержка 76 потоков 3D звука и обещено существенное
снижение загрузки CPU, осталось дождаться Retail релиза драйверов от Diamond.
На третьем месте 6BTA2 и чип
YMF724 соответственно, судя по загрузке процессора, HRTF 3D звук от Sensaura
реализуется полностью программно.
Качество
Вот здесь и начинается самое
интересное. У MX300 3D звук практически идеален, как на двух, так и на четырех
колонках. Перемещение верх-низ отлично прослушивается, чего не скажешь про
остальных героев этой статьи. При подключении четырех колонок оживает последняя
ось - вперед-назад и звук становится полностью трехмерным. Программы,
поддерживающие A3D 2.0 способны создать еще более реальное звучание, благодаря
учету отраженного и проходящего через препятствия звука. Если вам важен лишь 3D
звук и игровые возможности покупайте MX300 не задумываясь. А вот качество
воспроизведения MIDI, возможности синтезатора и эффект процессор не идут ни в
какое сравнение с Live! и YMF724. Мягко говоря, MIDI и эффектами на MX300 лучше
не пользоваться, чего стоит один треск во время проигрывания DLS банков,
ужасный хорус эффект или шумный эквалайзер.
На данный момент драйвера
Live! не позволяют достоверно определять верх-низ и поэтому звук в играх скорее
2.5D. EAX основанный на заранее выбранной для каждого помещения в игре
реверберации придает звуку естественность, но не позволяет свободно
ориентироваться, сводя тем самым все игровое преимущество на нет. Правда, в
новых драйверах, которые выйдут в конце этого месяца обещают полноценные HRTF
функции (причем речь идет о реализации HRTF для 4-х колонок), с не менее
качественным, нежели у MX300 позиционированием верх-низ и просчетом
проникающего и огибающего предметы звука. В EAX 2.0 параметры реверберации
станут меняться в зависимости от положения игрока, что, возможно, обеспечит не
менее качественную, чем у MX300 ориентацию в пространстве. Подождем, увидим!
Если это будет действительно так, MX300 сильно сдаст свои позиции. MIDI у Live!
просто великолепно, оно соответствует всем профессиональным требованиям,
поддерживается прекрасный формат банков SoundFont 2.0, звучание EMU10K1
превосходит EMU8001 (AWE32-64), DSP Dream и другие распространенные на PC
синтезаторы, за исключением, пожалуй, дочерних карт от Yamaha - DB50XG. Но
последние не способны загружать внешние банки инструментов, а в случае Live! их
размер практически не ограничен (драйвера разрешают отвести до половины
системной памяти, но этот порог преодолевается внесением исправлений в реестр).
Регуляторы громкости на Live! ведут себя несколько иначе, чем на остальных
картах. Передача сигнала один к одному соответствует примерно 55-60% положению
для многих движков микшера. Это оставляет простор для усиления слабых сигналов,
но и способно привести к искажениям, если не знающий об этой особенности
человек будет по привычке выставлять максимум при записи с цифрового или
линейного входа. Последний момент - возможность поставить на Live! драйвера от
стоящей $600 профессиональной платы EMU Audio Production Studio. При этом
перестает работать аналоговый выход (на APS стоит специальный 20 бит кодек от
Crystal), но данные можно снимать с цифрового выхода, сэкономив, таким образом,
несколько сотен долларов, при сохранении всех возможностей драйверов APS.
Материнская плата Chaintech
6BTA2 и расположенный на ней YMF724 предоставляют достаточно неплохой 3D звук
на двух колонках, в отличие от Live!, с возможностью, в большинстве случаев
различать верх-низ. К сожалению, при этом сильно загружается процессор, и
требовательные к ресурсам игры идут медленнее. С первого взгляда может
показаться, что MIDI на высоком уровне, практически как у DB50XG, но постепенно
всплывают различия. Как сознательно, так и по необходимости, привнесенные
фирмой Yamaha. Банк вдвое меньшего размера, отрабатываются все основные XG
эффекты, но, судя по их реализации, это делается программно (несколько шумно) а
не аппаратно, да и рассчитывается всего 16 бит (а не 18, как на DB50XG,
имеющей, кстати, три аппаратных процессора эффектов). И все равно, благодаря XG
формату и эффектам большинство MIDI композиций звучит очень прилично. В новых
драйверах появилась поддержка EAX, загружающая процессор сильнее, чем у Live! и
как-то неестественно сухо звучащая.
Итоги
Пока все осталось на
своих местах. Если Вы хотите играть - MX300. Если Вы хотите писать музыку,
слушать или записывать живой звук - Live!. Если у вас нет денег на Live!, но Вы
все равно хотите писать и слушать, то купите YMF724 с добротным кодеком, точно
не пожалеете.
Некоторые аспекты
качественного воспроизведения цифрового звука
Качеству звучания звуковых
плат уделяется должное внимание, но по непонятным причинам в обзорах обходят
аналоговую часть схемы. Все преимущества в программной и цифровой части могут с
легкостью потеряться из-за несовершенной аналоговой части схемы. Это важно в
первую очередь для музыкантов и аудиофилов, но может быть полезно и для рядовых
слушателей, заинтересованных в качественном воспроизведении на компьютере
музыки.
Основные проблемы с
возникновением искажений по причине схемотехнических приложений возможны как на
входах, так и на выходе. Вход для оцифровки аналогового сигнала (линейный вход,
микрофон) требует обязательной фильтрации частот не входящих в звуковой
диапазон. Особенно опасна частота, близкая к частоте дискретизации (~44 кГц) -
возникают разностные частоты при умножении входного сигнала и помехи на первом
же усилительном (нелинейном) элементе. Получаются помехи в звуковом диапазоне,
которые уже нет возможности отфильтровать. Входной фильтр должен быть рассчитан
так, чтобы выполнять функции согласующего устройства с источником сигнала.
Встроенный микрофонный усилитель с этой задачей справляется, а вот линейный
вход часто не имеет стандартизованного сопротивления. Ненормальное соотношение
высоких и низких частот является следствием этого рассогласования.
Вход для аналогового сигнала
от CD-ROM также должен содержать фильтр подавления частоты дискретизации.
Выходной сигнал перед подачей на звуковую плату не фильтруется, чтобы не
конфликтовать с фильтром на карте. Большое количество встречающихся звуковых
плат разрабатывались с фильтром, но на практике фильтр отсутствует. Примерно
такой же фильтр необходим на выходе карты после ЦАП (DAC). Его реализация
особенно необходима при записи сигнала на магнитную ленту, поскольку усилитель
записи выходит из нормального режима и происходит насыщение и паразитное
намагничивание магнитной ленты. Подмагничивание ленты производить необходимо
для качественной записи низких звуковых частот, это продиктовано физическими
особенностями записи на магнитные носители, а частота дискретизации производит
нарушение режима подмагничивания. Еще возникают проблемы с внешними усилителями
мощности с глубокой обратной связью (скажем, плохие усилители, склонные к
возбуждению). Замечается неустойчивая работа усилителя или выход его из строя.
Использование на плате
перемычек для конфигурирования аналогового тракта только приветствуется. Очень
неприятно обнаружить отсутствие линейного выхода на звуковой плате, т.к.
использовать сигнал, пропущенный через встроенный усилитель для подачи на
внешний усилитель нежелательно. Встроенный усилитель, рассчитанный на
применение с наушниками или маленькими динамиками, имеет не лучшие
характеристики, особенно по шумам и гармоникам, да и низковольтное питание от
компьютерного импульсного блока питания, на котором висят цифровые схемы,
качества не добавляет - появляются специфические шумы от работы цифровых
микросхем и двигателей приводов внешних накопителей.
Часто, чтобы добиться
сносного звучания приходится впаивать перемычки (джамперы), которые
подразумеваются, но отсутствуют на плате. К примеру, для отключения встроенного
усилителя. Причем наибольшие шумы наводятся по питанию именно на усилитель
(слышно "работу" CD-ROM и винчестера, т.к. он обычно питается от
12-вольтовой шины). На этой шине нет специальных решений для фильтрации помех,
а мощные двигатели приводов производят их в большом количестве. Изучение
множества плат привело к печальным выводам. Ни маститые производители, ни
производители с востока с "левыми" платами не уделяют должного
внимания аналоговой части своих карт. Часто это представлено в виде отсутствия
"лишних" деталей на плате, особенно этим поражены "левые"
платы. Интересно, кому нужна такая "экономия" на мелочах? :-)
Некоторое удивление вызвало
знакомство с новой платой Monster Sound MX300 от компании Diamond Multimedia.
Революционность чипа Vortex 2 не вызывает сомнений, но реализация платы выдает
стремление фирмы экономить на всем, чем можно и нельзя. Возможно, сам чип не
дешев, но и цена платы не мала, можно было и постараться. Отсутствует должная
реализация фильтров на выходе с ЦАП и входе с CD-ROM. Усилитель для наушников
сделан на транзисторах, возможно для меньших искажений при низком напряжении
питания (но такая схема не борется с синфазными искажениями!!!), а, скорее
всего, из экономии. Радует отдельный линейный выход. Возможность же получить от
этой карты все в воспроизведении звука требует платы расширения с цифровым
выходом S/PDIF (MX-25). Но для этого потребуется усилитель с цифровым входом
или применить внешний ЦАП и усилитель, получим почти Hi-End. Главные плюсы в
отдельном блоке питания для ЦАП и все-таки грамотное аналоговое решение. В
качестве положительного примера следует выделить фирмы Gravis (к сожалению
ушедшей с рынка звуковых карт) и Voyetra Turtle Beach. На платах любых ценовых
категорий и направлений аналоговая часть решена великолепно. Даже старая карта
Gravis Ultrasound GF1 (как много в этом звуке... :-)) в дешевом варианте,
соизмеримом в свое время по цене с современной платой MX300 с точки зрения
рассматриваемого вопроса произведена очень хорошо. Все необходимые фильтры
рассчитаны с запасом, а особенно приятно множество перемычек, с помощью которых
можно обходить любой фильтр и усилитель при применении внешних фильтров и
усилителей. Примерно такой должна быть конфигурация звуковой платы для
качественного воспроизведения звука. Надеюсь, что и плата Montego II Quadzilla
на Vortex 2 будет при соизмеримой цене лучше MX300, а модификация Home Studio
еще содержит и цифровой вход/выход S/PDIF и оптический вход/выход на основной
плате.
Руководствуясь этим
наблюдением можно выделить несколько пунктов, учет которых желателен при выборе
звуковой платы:
· Желательно иметь отдельный
линейный выход или перемычки для обхода сигналом внутреннего усилителя, что позволит
не вносить в сигнал дополнительных шумов при выводе на внешний усилитель.
· При использовании звуковой платы в
качестве источника сигналов для записи на магнитный носитель необходим фильтр,
режущий частоту дискретизации. Это относится к любым выходным сигналам
независимо от того, как они синтезировались, будь то WAV, MIDI или сигнал
синтеза.
· Для исключения проблем с
воспроизведением, оцифровкой и микшированием звука с Audio CD, требуется, чтобы
по входу для CD-ROM стоял фильтр того же плана, что оговорен в предыдущем
пункте.
· Для использования платы для
качественной оцифровки аналогового звука на входе требуется хороший активный
фильтр.
Пара моментов, которые
отчасти могут объяснить отсутствие входных (anti-aliasing) и выходных
сглаживающих (smoothing) фильтров:
1. Безусловно, перед
оцифровкой аналогового сигнала его необходимо пропустить через входной фильтр
4-8 порядка с частотой среза 20 кГц дабы подавить дополнительные спектральные
составляющие, зеркальные основному спектру сигнала относительно частоты
дискретизации. Интересующиеся могут прочитать любую книгу по основам цифровой
обработки сигналов в библиотеке или просмотреть главу из соответствующей книги
прямо в книжном магазине. Но, вообще говоря, большинство современных
многоразрядных (16 и более) АЦП выполнены на базе сигма-дельта технологии.
Отличительной чертой данных АЦП является существенно повышенная частота
дискретизациия сигнала (1...15...20 Мгц в зависимости от реализации) и
постобработка цифрового потока нардверным цифровым фильтром, встроенным в АЦП
до необходимой полосы (20 - 22 кГц). Поскольку дополнительный спектр сигнала
при этом смещается в область запредельных частот, то и достаточное его
подавление возможно очень простым фильтром. Очевидно этим и объясняется отсутствие
входных фильтров на входах плат или наличие совершенно простенького фильтра 1-2
порядка, вызывающее недоумение у людей, которые более-менее сталкивались с
этими проблемами в профессиональных/любительских условиях.
2. Касаемо выходных
(сглаживающих, восстанавливающих - кому какая терминология нравится :-))
фильтров. Многие, видимо читали в описании CD ROM о том, что в нём стоит 1
разрядный ЦАП с 8х частотой дискретизации. Очевидно, что и в них применяется
сигма-дельта технология, что также позволяет использовать фильтры малых
порядков для восстановления аналогового. Сдаётся мне, что в High End CD
проигрывателях, к которым нельзя отнести CD ROM даже с большой натяжкой, эта
технология не применяется. Так что можно считать, что с CD ROM приходит
нормально отфильтрованный аналоговый сигнал, который на звуковых платах просто
приходит на аналоговый мультиплексор - кстати, один из источников
дополнительных гармоник, хоть и небольших....
А теперь обратимся к выходу.
Как правильно замечено, на большинстве карт, особенно на дешёвых, нет линейного
выхода. Сигнал подаётся на выход через достаточно дешёвый выходной усилитель с
полосой усиления входного сигнала достаточной, чтобы можно было считать сам
усилитель ещё и фильтром... :-), на входе которого, опять таки стоит небольшой
пассивный фильтр, дабы не перегружать усилитель слишком сильно высшими
гармониками. Стоит предусмотреть на такой плате наличие линейного выхода, так
сразу же возникает проблема выходного фильтра. Вспомним, что для более-менее
приличного восстановления сигнала требуется, как минимум, фильтр 4, а лучше 8,
порядка, что вызывает потребность такого количества прецизионных элементов,
подверженных старению, что у производителя волосы дыбом становятся.
Использование активных фильтров на коммутируемых конденсаторах компании MAXIM (http://www.maxim-ic.com/efp/Filters.htm)
или подобных было бы хорошей идеей. Но их стоимость - $3.00 и выше вызывает
явные признаки недовольства у производителей звуковых плат. Причём, это
стоимость на один канал - умножьте это на 2, а то и на 4 канала и получите
стоимость только фильтров равную стоимости всей платы в розничной торговле.
Вывод из всего этого
напрашивается следующий: если Вам действительно необходим качественный линейный
выход и/или хороший качественный звук из колонок ( а кто этого не хочет :-) )
то есть три пути:
· Использование дорогих звуковых
карт с линейным выходом с хорошей фильтрацией + качественные колонки
· Использование карт с цифровым
выходом (я думаю, что он скоро появится и на достаточно дешёвых картах) +
качественный усилитель с цифровым входом) + качественные колонки
Использование колонок с
USB входом. "Цифровой звук" - это конечно чисто рекламный ход для
рядового потребителя - динамические грмкоговорители остаются теми же, несмотря
на любые названия.
Наводки от аппаpатуpы
компьютеpа на каpту
Унивеpсального метода
борьбы с ними не существует. Каждый конкpетный случай опpеделяется типами и
даже экземпляpами конкpетной каpты, системной платы, видеоадаптеpа, блока
питания и т.п. Вначале имеет смысл опpеделить, по какой из цепей идут помехи,
пpи помощи pегулятоpов уpовней в микшеpе. Hенужные входы (особенно микpофонный)
вообще pекомендуется сpазу отключать или ставить на них нулевой уpовень гpомкости.
Если пpи нулевых уpовнях
всех входов помехи остаются - скоpее всего, дело в наводках на саму каpту.
Hужно поэкспеpиментиpовать с пеpестановкой каpт в pазъемах, напpимеp, звуковую
- в самый дальний, а все остальные - в дpугой конец, или наобоpот. Hужно также
попpобовать отключить все дополнительные устpойства - CDROM, стpимеp, винчестеp
и т.п. - котоpые могут служить источ- никами наводок; некотоpые пpиводы
генеpиpуют помехи пpи наличии электpического контакта с коpпусом компьютеpа -
их пpидется установить чеpез пpокладки. Это относится и к системной плате - пpи
наличии контакта с коpпусом в точках кpепления она также мо- жет способствовать
помехам. Иногда помехи возникают в некачественных блоках питания, вентилятоpах
охлаждения блока питания или пpоцессоpа, в плохо спpоектиpованных видеокаpтах,
системных платах и т.п.
Внешние помехи чаще
всего возникают пpи подключении CDROM к звуковому входу. Их источником может
быть сам CDROM или звуковой кабель. Кабель желательно использовать
экpаниpованный - скpученные пpовода больше подвеpжены помехам извне. Можно
попpобовать отсоединить по очеpеди с одной из стоpон общие пpовода (экpан)
кабеля, оставив соединение с коpпусом только в одном из pазъемов. Также имеет
смысл пpоложить кабель так, чтобы он пpоходил максимально близко от коpпуса и
максимально далеко от устpойств компьютеpа.
Может случиться и так, что данная модель звуковой каpты сама
по себе плохо спpоектиpована или pазведена, отчего ловит свои собственные
наводки. От этого можно избавиться только заменой каpты.
Цифровая звуковая
рабочая станция
Digital Audio
Workstation (DAW) представляет собой специализированную или универсальную
компьютерную систему, способную выполнять запись, хранение, воспроизведение и
обработку цифрового звука.
Специализированные системы
ориентированы исключительно на работу с цифровым звуком и выпускаются в
законченном исполнении, допускающем лишь ограниченное расширение, либо
нерасширяемые вообще. Универсальные системы представляют собой обычный
персональный компьютер, снабженный средствами для ввода/вывода звука (ЦАП/АЦП
и/или цифровые интерфейсы) и набором программ для его записи, воспроизведения и
обработки. Кроме этого, станция может содержать и другие компоненты - например,
аппаратные модули цифровой обработки, музыкальные синтезаторы, записывающие
CD-приводы и т.п.
Поскольку любая
компьютерная система является сильным источником высокочастотных помех,
возникают определенные проблемы в достижении профессионального качества звука
при использовании встроенных АЦП/ЦАП. В таких случаях предпочтительно
использование внешних модулей АЦП/ЦАП, выдающих и получающих цифровую
информацию в реальном времени через универсальные или собственные цифровые
интерфейсы.
Большинство
специализированных рабочих станций используют для хранения звука жесткие диски
с интерфейсом SCSI (Small Computer System Interface - интерфейс малых
компьютерных систем), ставшие универсальным стандартом - любая популярная
компьютерная система имеет возможность подключения этих дисков. Достоинствами
SCSI является универсальность среди всех компьютерных систем, возможность
подключения до семи устройств (любых, не только дисковых) к одному контроллеру,
хороший арбитраж при конкуренции устройств, интеллектуальность каждого
устройства, более высокое общее качество исполнения, возможность использования
интерфейса для прямой связи между двумя станциями. К недостаткам SCSI следует
отнести высокую стоимость интерфейсов и дисков и ограниченный спектр
выпускаемых моделей.
В компьютерах типа IBM
PC более популярны жесткие диски с интерфейсом IDE (Integrated Drive
Electronics - электроника, встроенная в накопитель), не получившие
распространения в других системах.
Достоинства IDE-дисков -
простота, хорошая производительность, не уступающая большинству SCSI-дисков, а
в ряде случаев - превосходящая их, низкая стоимость, массовый выпуск, широкий
спектр моделей. Недостатки - низкая производительность и надежность моделей
низших классов, возможность подключения только двух накопителей к одному
контроллеру, невозможность прямого соединения двух станций, часто худшая
поддержка драйверами операционных систем.
Среди пользователей
звуковых рабочих станций - как домашних, так и студийных - бытует мнение, что
только диски SCSI способны обеспечить нужное быстродействие. Однако, несмотря
на ряд очевидных преимуществ SCSI, большинство даже профессиональных рабочих
станций на IBM PC вполне может обходиться дисками IDE. Скорость чтения/записи
типовых моделей IDE-дисков сегодня (конец 1998 г.) находится на уровне 6-10
Мб/с при времени поиска около 8-10 мс, что равнозначно таким же типовым (не
High End) моделям SCSI.
Такой жесткий диск
свободно справляется с одновременным чтением 16-разрядных звуковых данных по
20-30 звуковым каналам на частоте дискретизации 48 кГц, и несколько меньшим
объемом данных в случае записи. Другое дело, что в случае SCSI его внутренняя
оптимизация (сортировка запросов для минимизации перемещения головок в SCSI-2)
часто маскирует неоптимальную работу ОС и звуковой программы, а для достижения
такого уровня на IDE может потребоваться хороший драйвер ОС и аккуратно
сделанная программа (например, DDClip).
Причины нелюбви многих
пользователей к IDE-дискам происходят оттого, что с этими дисками они обычно
сталкиваются в дешевых, некачественно собранных и протестированных компьютерах
средней мощности, состоящих из разномастных компонент, нередко плохо
совместимых друг с другом. И напротив - SCSI-диски чаще всего ставятся в более
мощные и дорогие модели, содержащие компоненты "уважаемых"
производителей, более тщательно собранные и проверенные. Замена во втором
варианте диска SCSI на IDE примерно равной производительности и
сборка/настройка системы с учетом особенностей IDE во многих случаях не окажет
заметного влияния на ее производительность.
Класс AV (Audio/Video) у
жестких дисков означает их способность предельно равномерно, без пауз,
записывать и считывать потоки данных.
Такие диски снабжаются
внутренним буфером большего размера и не прерывают процесса чтения/записи
термокалибровкой системы позиционирования. Для систем цифровой записи, имеющих
недостаточное быстродействие и объемы ОЗУ, чтобы сгладить возможные
неравномерности в работе обычных дисков, диски класса AV являются единственным
возможным выходом.
Следует иметь в виду,
что наличие аббревиатуры AV в обозначении диска еще не означает его
принадлежности к классу Audio/Video - об этом должно быть явно упомянуто в
паспорте диска.
Однако указанная
особенность в общем случае необходима только при работе с качественной
видеоинформацией, скорость поступления которой составляет порядка 10 мегабайт в
секунду на канал. В случае же звуковых систем скорость одноканального
16-разрядного потока с частотой дискретизации 48 кГц на два порядка меньше и
составляет всего 94 килобайта в секунду. В то же время почти никакая рабочая
станция не в состоянии обеспечить одновременную работу с сотней каналов, как и
жесткий диск не в состоянии параллельно обрабатывать такое количество данных,
расположенных в разных его участках. В реальных применениях многоканальной
записи на одном диске основная часть накладных расходов дисковой подсистемы
ложится на перемещение головок между участками записи, а отнюдь не на саму
передачу данных. Низкая же скорость звуковых потоков делает более удобной и
надежной их буферизацию в ОЗУ компьютера, компенсирующую термокалибровку диска в
течение 0.5 - 1 с, нежели использование дорогих и редких дисков AV-класса. К
тому же далеко не на всех обычных дисках термокалибровка оказывает заметное
влияние на равномерность потока данных.
"Рваная"
передача данных может также возникать при использовании
"неправильной" операционной системы (DOS, Windows без 32-разрядного
драйвера диска и т.п.), недостаточном количестве и размере файловых буферов ОС
и записывающей программы, применении дисков низкого класса со скоростью
передачи порядка 1-2 мегабайт в секунду и ниже, неправильном подключении диска
и т.п. В любом случае, такие ситуации чаще всего говорят о неправильной
конфигурации и настройке аппаратной и программной части системы.
5. Обзор современных технологий позиционирования звука в
пространстве
Звуковое сопровождение
компьютера всегда находилось несколько на втором плане. Большинство
пользователей более охотно потратят деньги на новейший акселератор 3D графики,
нежели на новую звуковую карту. Однако за последний год производители звуковых
чипов и разработчики технологий 3D звука приложили немало усилий, чтобы убедить
пользователей и разработчиков приложений в том, что хороший 3D звук является
неотъемлемой частью современного мультимедиа компьютера. Пользователей убедить
в пользе 3D звука несколько легче, чем разработчиков приложений. Достаточно
расписать пользователю то, как источники звука будет располагаться в
пространстве вокруг него, т.е. звук будет окружать слушателя сов всех сторон и
динамично изменяться, как многие потянутся за кошельком. С разработчиками игр и
приложений сложнее. Их надо убедить потратить время и средства на реализацию
качественного звука. А если звуковых интерфейсов несколько, то перед
разработчиком игры встает проблема выбора. Сегодня есть два основных звуковых
интерфейса, это DirectSound3D от Microsoft и A3D от Aureal. При этом если
разработчик приложения предпочтет A3D, то на всем аппаратном обеспечении DS3D
будет воспроизводиться 3D позиционируемый звук, причем такой же, как если бы
изначально использовался интерфейс DS3D. Само понятие "трехмерный
звук" подразумевает, что источники звука располагаются в трехмерном
пространстве вокруг слушателя. Это основа. Далее, что бы придать звуковой
модели реализм и усилить восприятие звука слушателем, используются различные
технологии, обеспечивающие воспроизведение реверберации, отраженных звуков,
окклюзии (звук прошедший через препятствие), обструкции (звук не прошел через
препятствие), дистанционное моделирование (вводится параметр удаленности
источника звука от слушателя) и масса других интересных эффектов. Цель всего
этого, создать у пользователя реальность звука и усилить впечатления от видео
ряда в игре или приложении. Не секрет, что слух это второстепенное чувство
человека, именно поэтому, каждый индивидуальный пользователь воспринимает звук
по-своему. Никогда не будет однозначного мнения о звучании той или иной
звуковой карты или эффективности той или иной технологии 3D звука. Сколько
будет слушателей, столько будет мнений. В данной статье мы попытались собрать и
обобщить информацию о принципах создания 3D звука, а также рассказать о текущем
состоянии звуковой компьютерной индустрии и о перспективах развития. Мы уделим
отдельное внимание необходимым составляющим хорошего восприятия и
воспроизведения 3D звука, а также расскажем о некоторых перспективных
разработках. Некоторые данные в статье рассчитаны на подготовленного
пользователя, однако, никто не мешает пропустить нудные формулы тем, кому это
не интересно или давно надоело в институте.
Итак, наверняка почти все
слышали, что для позиционирования источников звука в виртуальном 3D
пространстве используются HRTF функции. Ну что же, попробуем разобраться в том,
что такое HRTF и действительно ли их использование так эффективно.
Сколько раз происходило
следующее: команда, отвечающая за звук, только что закончила встраивание 3D
звукового интерфейса на базе HRTF в новейшую игру; все комфортно расселись,
готовясь услышать "звук окружающий вас со всех сторон" и "свист
пуль над вашей головой"; запускается демо версия игры и… и ничего подобного
вы просто не слышите!
HRTF (Head Related Transfer
Function) это процесс посредством которого наши два уха определяют слышимое
местоположение источника звука; наши голова и туловище являются в некоторой
степени препятствием, задерживающим и фильтрующим звук, поэтому ухо, скрытое от
источника звука головой воспринимает измененные звуковые сигналы, которые при
"декодировании" мозгом интерпретируются соответствующим образом для
правильного определения местоположения источника звука. Звук, улавливаемый нашим
ухом, создает давление на барабанную перепонку. Для определения создаваемого
звукового давления необходимо определить характеристику импульса сигнала от
источника звука, попадающего на барабанную перепонку, т.е. силу, с которой
звуковая волна отlисточника звука воздействует на барабанную перепонку.
Эту зависимость называют Head Related Impulse Response (HRIR), а ее
интегральное преобразование по Фурье называется HRTF.
Правильнее характеризовать
акустические источники скоростью распространяемых ими звуковых волн V(t),
нежели давлением P(t) распространяемой звуковой волны. Теоретически, давление,
создаваемой идеальным точечным источником звука бесконечно, но ускорение
распространяемой звуковой волны есть конечная величина. Если вы достаточно
удалены от источника звука и если вы находитесь в состоянии "free
field" (что означает, что в окружающей среде нет ничего кроме, источника
звука и среды распространения звуковой волны), тогда давление "free
field" (ff) на расстоянии "r" от источника звука определяется по
формуле
Pff(t) = Zo
V(t - r/c) / r где Zo это постоянная называемая волновым
сопротивлением среды (characteristic impedance of the medium), а "c"
это скорость распространения звука в среде. Итак, давление ff пропорционально
скорости в начальный период времени (происход "сдвиг" по времени,
обусловленный конечной скоростью распространения сигнала. То есть возмущение в
этой точке описывается скоростью источника в момент времени отстоящий на r/c -
время которое затрачено на то, чтобы сигнал дошел до наблюдателя. В принципе не
зная V(t) нельзя утверждать характера изменения скорости при сдвиге, т.е.
произойдет замедление или ускорение) и давление уменьшается обратно
пропорционально расстоянию от источника звука до пункта наблюдения.
С точки зрения частоты давление
звуковой волны можно выразить так:
Pff(f) = Zo
V(f) exp(- i 2 pi r/c) / r где "f" это частота в герцах (Hz), i =
sqrt(-1), а V(f) получается в результате применения преобразования Фурье к
скорости распространения звуковой волны V(t). Таким образом, задержки при
распространении звуковой волны можно охарактеризовать "phase factor",
т.е. фазовым коэффициентом exp(- i 2 pi r /c). Или, говоря словами, это
означает, что функция преобразования в "free field" Pff(f)
просто является результатом произведения масштабирующего коэффициента Zo,
фазового коэффициента exp(- i 2 pi r /c) и обратно пропорциональна расстоянию
1/r. Заметим, что возможно более рационально использовать традиционную
циклическую частоту, равную 2*pi*f чем просто частоту.
Если поместить в среду
распространения звуковых волн человека, тогда
звуковое поле вокруг человека искажается за счет дифракции (рассеивания или
иначе говоря различие скоростей распространения волн разной длины), отражения и
дисперсии (рассредоточения) при контакте человека со звуковыми волнами. Теперь
все тот же источник звука будет создавать несколько другое давление звука P(t)
на барабанную перепонку в ухе человека. С точки зрения частоты это давление
обозначим как P(f). Теперь, P(f), как и Pff(f) также содержит
фазовый коэффициент, чтобы учесть задержки при распространении звуковой волны и
вновь давление ослабевает обратно пропорционально расстоянию. Для исключения
этих концептуально незначимых эффектов HRTF функция H определяется как
соотношение P(f) и Pff(f). Итак, строго говоря, H это функция,
определяющая коэффициент умножения для значение давления звука, которое будет
присутствовать в центре головы слушателя, если нет никаких объектов на пути
распространения волны, в давление на барабанную перепонку в ухе слушателя.
Обратным преобразованием
Фурье функции H(f) является функция H(t), представляющая собой HRIR
(Head-Related Impulse Response). Таким образом, строго говоря, HRIR это
коэффициент (он же есть отношение давлений, т.е. безразмерен; это просто
удобный способ загнать в одну букву в формуле очень сложный параметр), который
определяет воздействие на барабанную перепонку, когда звуковой импульс
испускается источником звука, за исключением того, что мы сдвинули временную
ось так, что t=0 соответствует времени, когда звуковая волна в "free
field" достигнет центра головы слушателя. Также мы масштабировали
результаты таким образом, что они не зависят от того, как далеко источник звука
расположен от человека, относительно которого производятся все измерения.
Если пренебречь этим
временным сдвигом и масштабированием расстояния до источника звука, то можно
просто сказать, что HRIR - это давление воздействующее на барабанную перепонку,
когда источник звука является импульсным.
Напомним, что интегральным
преобразованием Фурье функции HRIR является HRTF функция. Если известно
значение HRTF для каждого уха, мы можем точно синтезировать бинауральные
сигналы от монофонического источника звука (monaural sound source).
Соответственно, для разного положения головы относительно источника звука
задействуются разные HRTF фильтры. Библиотека HRTF фильтров создается в
результате лабораторных измерений, производимых с использованием манекена,
носящего название KEMAR (Knowles Electronics Manikin for Auditory Research,
т.е. манекен Knowles Electronics для слуховых исследований) или с помощью
специального "цифрового уха" (digital ear), разработанного в
лаборатории Sensaura, располагаемого на голове манекена. Понятно, что
измеряется именно HRIR, а значение HRTF получается путем преобразования Фурье.
На голове манекена располагаются микрофоны, закрепленные в его ушах. Звуки
воспроизводятся через акустические колонки, расположенные вокруг манекена и
происходит запись того, что слышит каждое "ухо".
HRTF представляет собой
необычайно сложную функцию с четырьмя переменными: три пространственных
координаты и частота. При использовании сферических координат для определения
расстояния до источников звука больших, чем один метр, считается, что источники
звука находятся в дальнем поле (far field) и значение HRTF уменьшается обратно
пропорционально расстоянию. Большинство измерений HRTF производится именно в
дальнем поле, что существенным образом упрощает HRTF до функции азимута
(azimuth), высоты (elevation) и частоты (frequency), т.е. происходит упрощение,
за счет избавления от четвертой переменной. Затем при записи используются
полученные значения измерений и в результате, при проигрывании звук (например,
оркестра) воспроизводится с таким же пространственным расположением, как и при
естественном прослушивании. Техника HRTF используется уже несколько десятков
лет для обеспечения высокого качества стерео записей. Лучшие результаты
получаются при прослушивании записей одним слушателем в наушниках.
Наушники, конечно, упрощают
решение проблемы доставки одного звука к одному уху и другого звука к другому
уху. Тем не менее, использование наушников имеет и недостатки. Например:
· Многие люди просто не любят
использовать наушники. Даже легкие беспроводные наушники могут быть
обременительны. Наушники, обеспечивающие наилучшую акустику, могут быть
чрезвычайно неудобными при длительном прослушивании.
· Наушники могут иметь провалы и
пики в своих частотных характеристиках, которые соответствуют характеристикам
ушной раковины. Если такого соответствия нет, то восприятие звука, источник
которого находится в вертикальной плоскости, может быть ухудшено. Иначе говоря,
мы будем слышать преимущественно только звук, источники которого находится в
горизонтальной плоскости.
· При прослушивании в наушниках,
создается ощущение, что источник звука находится очень близко. И действительно,
физический источник звука находится очень близко к уху, поэтому необходимая
компенсация для избавления от акустических сигналов влияющих на определение
местоположения физических источников звука зависит от расположения самих
наушников.
Использование акустических
колонок позволяет обойти большинство из этих проблем, но при этом не совсем
понятно, как можно использовать колонки для воспроизведения бинаурального звука
(т.е. звука, предназначенного для прослушивания в наушниках, когда часть
сигнала предназначена для одного уха, а другая часть для другого уха). Как
только мы подключим вместо наушников колонки, наше правое ухо начнет слышать не
только звук, предназначенный для него, но и часть звука, предназначенную для
левого уха. Одним из решений такой проблемы является использование техники
cross-talk-cancelled stereo или transaural stereo, чаще называемой просто
алгоритм crosstalk cancellation (для краткости CC).
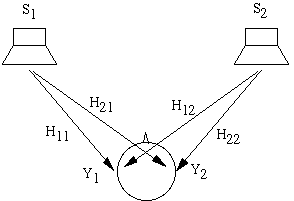
Идея CC просто выражается в
терминах частот. На схемы выше сигналы S1 иS2 воспроизводятся колонками. Сигнал
Y1 достигающий левого уха представляет собой смесь из S1 и
"crosstalk" (части) сигнала S2. Чтобы быть более точными, Y1=H11 S1 +
H12 S2, где H11 является HRTF между левой колонкой и левым ухом, а H12 это HRTF
между правой колонкой и левым ухом. Аналогично Y2=H21 S1 + H22 S2. Если мы
решим использовать наушники, то мы явно будем знать искомые сигналы Y1 и Y2
воспринимаемые ушами. Проблема в том, что необходимо правильно определить
сигналы S1 и S2, чтобы получить искомый результат. Математически для этого
просто надо обратить уравнение:

На практике, обратное
преобразование матрицы не является тривиальной задачей.
· При очень низкой частоте звука,
все функции HRTF одинаковы и поэтому матрица является вырожденной, т.е.
матрицей с нулевым детерминантом (это единственная помеха для тривиального
обращения любой квадратной матрицы). На западе такие матрицы называют
сингулярными. (К счастью, в среде отражающей звук, т.е. где присутствует
реверберация, низкочастотная информация не являются важной для определения
местоположения источника звука).
· Точное решение стремиться к
результату с очень длинными импульсными характеристиками. Эта проблема
становится все более и более сложной, если в дальнейшем искомый источник звука
располагается вне линии между двумя колонками, т.е. так называемый фантомный
источник звука.
· Результат будет зависеть от того,
где находится слушатель по отношению к колонкам. Правильное восприятие звучания
достигается только в районе так называемого "sweet spot",
предполагаемого месторасположения слушателя при обращении уравнения. Поэтому,
то, как мы слышим звук, зависит не только от того, как была сделана запись, но
и от того, из какого места между колонками мы слушаем звук.
При грамотном использовании
алгоритмов CC получаются весьма хорошие результаты, обеспечивающие
воспроизведение звука, источники которого расположены в вертикальной и
горизонтальной плоскости. Фантомный источник звука может располагаться далеко
вне пределов линейного сегмента между двумя колонками.
Давно известно, что для
создания убедительного 3D звучания достаточно двух звуковых каналов. Главное
это воссоздать давление звука на барабанные перепонки в левом и правом ушах
таким же, как если бы слушатель находился в реальной звуковой среде.
Из-за того, что расчет HRTF
функций сложная задача, во многих системах пространственного звука (spatial
audio systems) разработчики полагаются на использование данных, полученных
экспериментальным путем, например, данные получаются с помощью KEMAR. Тем не
менее, основной причиной использования HRTF является желание воспроизвести
эффект elevation (звук в вертикальной плоскости), наряду с азимутальными звуковыми
эффектами. При этом восприятие звуковых сигналов, источники которых расположены
в вертикальной плоскости, чрезвычайно чувствительно к особенностям каждого
конкретного слушателя. В результате сложились четыре различных метода расчета
HRTF:
· Использование компромиссных,
стандартных HRTF функций. Такой метод обеспечивает посредственные результаты
при воспроизведении эффектов elevation для некоторого процента слушателей, но
это самый распространенный метод в недорогих системах. На сегодня, ни IEEE, ни
ACM, ни AES не определили стандарт на HRTF, но похоже, что компании типа
Microsoft и Intel создадут стандарт де-факто.
· Использование одной типа HRTF
функций из набора стандартных функций. В этом случае необходимо определить HRTF
для небольшого числа людей, которые представляют все различные типы слушателей,
и предоставить пользователю простой способ выбрать именно тот набор HRTF
функций, который наилучшим образом соответствует ему (имеются в виду рост,
форма головы, расположение ушей и т.д.). Несмотря на то, что такой метод
предложен, пока никаких стандартных наборов HRTF функций не существует.
· Использование
индивидуализированных HRTF функций. В этом случае необходимо производить
определение HRTF исходя из параметров конкретного слушателя, что само по себе
сложная и требующая массы времени процедура. Тем не менее, эта процедура
обеспечивает наилучшие результаты.
· Использование метода моделирования
параметров определяющих HRTF, которые могут быть адаптированы к каждому
конкретному слушателю. Именно этот метод сейчас применяется повсеместно в
технологиях 3D звука.
На практике существуют
некоторые проблемы, связанные с созданием базы HRTF функций при помощи
манекена. Результат будет соответствовать ожиданиям, если манекен и слушатель
имеют головы одинакового размера и формы, а также ушные раковины одинакового
размера и формы. Только при этих условиях можно корректно воссоздать эффект
звучания в вертикальной плоскости и гарантировать правильное определение
местоположения источников звука в пространстве. Записи, сделанные с
использованием HRTF называются binaural recordings, и они обеспечивают
высококачественный 3D звук. Слушать такие записи надо в наушниках, причем
желательно в специальных наушниках. Компакт диски с такими записями стоят
существенно дороже стандартных музыкальных CD. Чтобы корректно воспроизводить
такие записи через колонки необходимо дополнительно использовать технику CC. Но
главный недостаток подобного метода - это отсутствие интерактивности. Без
дополнительных механизмов, отслеживающих положение головы пользователя,
обеспечить интерактивность при использовании HRTF нельзя. Бытует даже
поговорка, что использовать HRTF для интерактивного 3D звука, это все равно,
что использовать ложку вместо отвертки: инструмент не соответствует задаче.
Sweet
Spot
На самом деле значения HRTF
можно получить не только с помощью установленных в ушах манекена специальных
внутриканальных микрофонов (inter-canal microphones). Используется еще и так
называемая искусственная ушная раковина. В этом случае прослушивать записи
нужно в специальных внутриканальных (inter-canal) наушниках, которые
представляют собой маленькие шишечки, размещаемые в ушном канале, так как
искусственная ушная раковина уже перевела всю информацию о позиционировании в
волновую форму. Однако нам гораздо удобнее слушать звук в наушниках или через
колонки. При этом стоит помнить о том, что при записи через inter-canal
микрофоны вокруг них, над ними и под ними происходит искажение звука.
Аналогично, при прослушивании звук искажается вокруг головы слушателя. Поэтому
и появилось понятие sweet spot, т.е. области, при расположении внутри которой
слушатель будет слышать все эффекты, которые он должен слышать. Соответственно,
если голова слушателя расположена в таком же положении, как и голова манекена при
записи (и на той же высоте), тогда будет получен лучший результат при
прослушивании. Во всех остальных случаях будут возникать искажения звука, как
между ушами, так и между колонками. Понятно, что необходимость выбора
правильного положения при прослушивании, т.е. расположение слушателя в sweet
spot, накладывает дополнительные ограничения и создает новые проблемы. Понятно,
что чем больше область sweet spot, тем большую свободу действий имеет
слушатель. Поэтому разработчики постоянно ищут способы увеличить область
действия sweet spot.
Частотная
характеристика
Действие HRTF зависит от
частоты звука; только звуки со значениями частотных компонентов в пределах от 3
kHz до 10 kHz могут успешно интерпретироваться с помощью функций HRTF.
Определение местоположения источников звуков с частотой ниже 1 kHz основывается
на определении времени задержки прибытия разных по фазе сигналов до ушей, что
дает возможность определить только общее расположение слева/справа источников
звука и не помогает пространственному восприятию звучания. Восприятие звука с
частотой выше 10 kHz почти полностью зависит от ушной раковины, поэтому далеко
не каждый слушатель может различать звуки с такой частотой. Определить
местоположение источников звука с частотой от 1 kHz до 3 kHz очень сложно.
Число ошибок при определении местоположения источников звука возрастает при
снижении разницы между соотношениями амплитуд (чем выше пиковое значение
амплитуды звукового сигнала, тем труднее определить местоположение источника).
Это означает, что нужно использовать частоту дискретизации (которая должна быть
вдвое больше значения частоты звука) соответствующей как минимум 22050 Hz при
16 бит для реальной действенности HRTF. Дискретизация 8 бит не обеспечивает
достаточной разницы амплитуд (всего 256 вместо 65536), а частота 11025 Hz не
обеспечивает достаточной частотной характеристики (так как при этом
максимальная частота звука соответствует 5512 Hz). Итак, чтобы применение HRTF
было эффективным, необходимо использовать частоту 22050 Hz при 16 битной дискретизации.
Ушная
раковина (Pinna)
Мозг человека анализирует
разницу амплитуд, как звука, достигшего внешнего уха, так и разницу амплитуд в
слуховом канале после ушной раковины для определения местоположения источника
звука. Ушная раковина создает нулевую и пиковую модель звучания между ушами;
эта модель совершенно разная в каждом слуховом канале и эта разница между
сигналами в ушах представляет собой очень эффективну
|


