Студентам > Курсовые > Многопроцессорный вычислительный комплекс на основе коммутационной матрицы
Многопроцессорный вычислительный комплекс на основе коммутационной матрицыСтраница: 2/4
Как
видно из этого рисунка, все нити процесса выполняются в его контексте, но
каждая нить имеет свой собственный контекст. Контекст нити, как и контекст
процесса, состоит из пользовательской и ядерной составляющих. Пользовательская
составляющая контекста нити включает индивидуальный стек нити. Поскольку нити
одного процесса выполняются в общей виртуальной памяти, все нити процесса имеют
равные права доступа к любым частям виртуальной памяти процесса, стек (сегмент
стека) любой нити процесса в принципе не защищен от произвольного (например, по
причине ошибки) доступа со стороны других нитей. Ядерная составляющая контекста
нити включает ее регистровый контекст (в частности, содержимое регистра
счетчика команд) и динамически создаваемые ядерные стеки.
Приведенное
краткое обсуждение понятия нити кажется достаточным для того, чтобы понять, что
внедрение в ОС механизма легковесных процессов требует существенных переделок
ядра системы. (Всегда трудно внедрить в программу средства, для поддержки
которых она не была изначально приспособлена.)
3.2.1 Подходы
к организации нитей и управлению ими в разных вариантах ОС UNIX
Хотя
концептуально реализации механизма нитей в разных современных вариантах
практически эквивалентны (да и что особенное можно придумать по поводу
легковесных процессов?), технически и, к сожалению, в отношении интерфейсов эти
реализации различаются. Мы не ставим здесь перед собой цели описать в деталях
какую-либо реализацию, однако постараемся в общих чертах охарактеризовать
разные подходы.
Начнем
с того, что разнообразие механизмов нитей в современных вариантах ОС UNIX само
по себе представляет проблему. Сейчас достаточно трудно говорить о возможности
мобильного параллельного программирования в среде UNIX-ориентированных
операционных систем. Если программист хочет добиться предельной эффективности
(а он должен этого хотеть, если для целей его проекта приобретен дорогостоящий
мультипроцессор), то он вынужден использовать все уникальные возможности
используемой им операционной системы.
Для
всех очевидно, что сегодняшняя ситуация далека от идеальной. Однако,
по-видимому, ее было невозможно избежать, поскольку поставщики симметричных
мультипроцессорных архитектур должны были как можно раньше предоставить своим
покупателям возможности эффективного программирования, и времени на
согласование решений просто не было (любых поставщиков прежде всего интересует
объем продаж, а проблемы будущего оставляются на будущее).
Применяемые
в настоящее время подходы зависят от того, насколько внимательно разработчики
ОС относились к проблемам реального времени. (Возвращаясь к введению этого
раздела, еще раз отметим, что здесь мы имеем в виду "мягкое" реальное
время, т. е. программно-аппаратные системы, которые обеспечивают быструю
реакцию на внешние события, но время реакции не установлено абсолютно строго.)
Типичная система реального времени состоит из общего монитора, который
отслеживает общее состояние системы и реагирует на внешние и внутренние
события, и совокупности обработчиков событий, которые, желательно параллельно,
выполняют основные функции системы.
Понятно,
что от возможностей реального распараллеливания функций обработчиков зависят
общие временные показатели системы. Если, например, при проектировании системы
замечено, что типичной картиной является "одновременное" поступление
в систему N внешних событий, то желательно гарантировать наличие реальных N
устройств обработки, на которых могут базироваться обработчики. На этих
наблюдениях основан подход компании Sun Microsystems.
В
системе Solaris (правильнее говорить SunOS 4.x, поскольку Solaris в
терминологии Sun представляет собой не операционную систему, а расширенную
операционную среду) принят следующий подход. При запуске любого процесса можно
потребовать резервирования одного или нескольких процессоров мультипроцессорной
системы. Это означает, что операционная система не предоставит никакому другому
процессу возможности выполнения на зарезервированном(ых) процессоре(ах).
Независимо от того, готова ли к выполнению хотя бы одна нить такого процесса,
зарезервированные процессоры не будут использоваться ни для чего другого.
Далее,
при образовании нити можно закрепить ее за одним или несколькими процессорами
из числа зарезервированных. В частности, таким образом, в принципе можно
привязать нить к некоторому фиксированному процессору. В общем случае некоторая
совокупность потоков управления привязывается к некоторой совокупности
процессоров так, чтобы среднее время реакции системы реального времени
удовлетворяло внешним критериям. Очевидно, что это "ассемблерный"
стиль программирования (слишком много перекладывается на пользователя), но зато
он открывает широкие возможности перед разработчиками систем реального времени
(которые, правда, после этого зависят не только от особенностей конкретной
операционной системы, но и от конкретной конфигурации данной компьютерной
установки). Подход Solaris преследует цели удовлетворить разработчиков систем
"мягкого" (а, возможно, и "жесткого") реального времени, и
поэтому фактически дает им в руки средства распределения критических
вычислительных ресурсов.
В
других подходах в большей степени преследуется цель равномерной балансировки
загрузки мультипроцессора. В этом случае программисту не предоставляются
средства явной привязки процессоров к процессам или нитям. Система допускает
явное распараллеливание в пределах общей виртуальной памяти и
"обещает", что по мере возможностей все процессоры вычислительной
системы будут загружены равномерно. Этот подход обеспечивает наиболее
эффективное использование общих вычислительных ресурсов мультипроцессора, но не
гарантирует корректность выполнения систем реального времени (если не считать
возможности установления специальных приоритетов реального времени).
Отметим
существование еще одной аппаратно-программной проблемы, связанной с нитями (и
не только с ними). Проблема связана с тем, что в существующих симметричных
мультипроцессорах обычно каждый процессор обладает собственной
сверхбыстродействующей буферной памятью (кэшем). Идея кэша, в общих чертах,
состоит в том, чтобы обеспечить процессору очень быстрый (без необходимости
выхода на шину доступа к общей оперативной памяти) доступ к наиболее актуальным
данным. В частности, если программа выполняет запись в память, то это действие
не обязательно сразу отображается в соответствующем элементе основной памяти;
до поры до времени измененный элемент данных может содержаться только в
локальном кэше того процессора, на котором выполняется программа. Конечно, это
противоречит идее совместного использования виртуальной памяти нитями одного
процесса (а также идее использования памяти, разделяемой между несколькими
процессами).
Это
очень сложная проблема, относящаяся к области проблем "когерентности
кэшей". Теоретически имеется много подходов к ее решению (например,
аппаратное распознавание необходимости выталкивания записи из кэша с синхронным
объявлением недействительным содержания всех кэшей, включающих тот же элемент
данных). Однако на практике такие сложные действия не применяются, и обычным
приемом является отмена режима кэширования в том случае, когда на разных
процессорах мультипроцессорной системы выполняются нити одного процесса или
процессы, использующие разделяемую память.
После
введения понятия нити трансформируется само понятие процесса. Теперь лучше (и
правильнее) понимать процесс ОС UNIX как некоторый контекст, включающий
виртуальную память и другие системные ресурсы (включая открытые файлы), в
котором выполняется, по крайней мере, один поток управления (нить), обладающий
своим собственным (более простым) контекстом. Теперь ядро знает о существовании
этих двух уровней контекстов и способно сравнительно быстро изменять контекст
нити (не изменяя общего контекста процесса) и так же, как и ранее, изменять
контекст процесса. Последнее замечание относится к синхронизации выполнения
нитей одного процесса (точнее было бы говорить о синхронизации доступа нитей к
общим ресурсам процесса - виртуальной памяти, открытым файлам и т. д.).
Конечно, можно пользоваться (сравнительно) традиционными средствами
синхронизации (например, семафорами). Однако оказывается, что система может предоставить
для синхронизации нитей одного процесса более дешевые средства (поскольку все
нити работают в общем контексте процесса). Обычно эти средства относятся к
классу средств взаимного исключения (т. е. к классу семафороподобных средств).
К сожалению, и в этом отношении к настоящему времени отсутствует какая-либо
стандартизация.
3.3 Семафоры
Поддержка операционной системы в
многопроцессорной конфигурации может включать в себя разбиение ядра системы на
критические участки, параллельное выполнение которых на нескольких процессорах
не допускается. Нижеследующие рассуждения помогают понять суть данной
особенности. При ближайшем рассмотрении сразу же возникают два вопроса: как
использовать семафоры и где определить критические участки.
Если при выполнении критического участка
программы процесс приостанавливается, для защиты участка от посягательств со
стороны других процессов алгоритмы работы ядра однопроцессорной операционной
системы используют блокировку.
Механизм установления блокировки:
/* операция проверки */
выполнять пока (блокировка
установлена)
{
приостановиться
(до снятия блокировки);
};
установить блокировку;
Механизм снятия блокировки:
снять блокировку;
вывести из состояния
приостанова все процессы, приостановленные в результате блокировки;
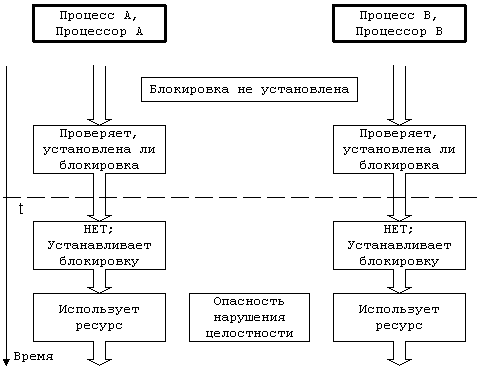
Блокировки такого рода охватывают некоторые
критические участки, но не работают в многопроцессорных системах, что видно из
приведенного рисунка:
|
|
|
|
|
Предположим, что блокировка снята, и что два
процесса на разных процессорах одновременно пытаются проверить ее наличие и
установить ее. В момент t они обнаруживают снятие блокировки, устанавливают ее
вновь, вступают в критический участок и создают опасность нарушения целостности
структур данных ядра. В условии одновременности имеется отклонение: механизм не
сработает, если перед тем, как процесс выполняет операцию проверки, ни один
другой процесс не выполнил операцию установления блокировки. Если, например,
после обнаружения снятия блокировки процессор A обрабатывает прерывание и в
этот момент процессор B выполняет проверку и устанавливает блокировку, по
выходе из прерывания процессор A так же установит блокировку. Чтобы
предотвратить возникновение подобной ситуации, нужно сделать так, чтобы
процедура блокирования была неделимой: проверку наличия блокировки и ее установку
следует объединить в одну операцию, чтобы в каждый момент времени с блокировкой
имел дело только один процесс.
3.3.1 Определение
семафоров
Семафор представляет собой обрабатываемый ядром
целочисленный объект, для которого определены следующие элементарные
(неделимые) операции:
· Инициализация
семафора, в результате которой семафору присваивается неотрицательное значение;
· Операция
типа P, уменьшающая значение семафора. Если значение семафора опускается ниже
нулевой отметки, выполняющий операцию процесс приостанавливает свою работу;
· Операция
типа V, увеличивающая значение семафора. Если значение семафора в результате
операции становится больше или равно 0, один из процессов, приостановленных во
время выполнения операции P, выходит из состояния приостанова;
· Условная
операция типа P, сокращенно CP (conditional P), уменьшающая значение семафора и
возвращающая логическое значение "истина" в том случае, когда
значение семафора остается положительным. Если в результате операции значение
семафора должно стать отрицательным или нулевым, никаких действий над ним не
производится и операция возвращает логическое значение "ложь".
Определенные таким образом семафоры, безусловно,
никак не связаны с семафорами пользовательского уровня.
3.3.2 Реализация
семафоров
Дийкстра показал, что семафоры можно реализовать
без использования специальных машинных инструкций. Здесь представлены
реализующие семафоры функции, написанные на языке Си.
struct semaphore
{
int val[NUMPROCS]; /* замок -
1 элемент на каждый процессор */
int lastid; /* идентификатор
процессора, получившего семафор последним */
};
int procid; /* уникальный
идентификатор процессора */
int lastid; /* идентификатор
процессора, получившего семафор последним */
Init(semaphore)
struct semaphore semaphore;
{
int i;
for (i = 0; i < NUMPROCS; i++)
semaphore.val[i] = 0;
}
Pprim(semaphore)
struct semaphore semaphore;
{
int i,first;
loop:
first = lastid;
semaphore.val[procid] = 1;
forloop:
for (i = first; i < NUMPROCS; i++)
{
if (i == procid)
{
semaphore.val[i] = 2;
for (i = 1; i < NUMPROCS; i++)
if (i != procid && semaphore.val[i] == 2)
goto loop;
lastid = procid;
return;
/* успешное завершение,
ресурс можно использовать */
}
else if (semaphore.val[i])
goto loop;
}
first = 1;
goto forloop;
}
Vprim(semaphore)
struct semaphore semaphore;
{
lastid = (procid + 1) %
NUMPROCS; /* на следующий процессор */
semaphore.val[procid] = 0;
}
Функция Pprim блокирует семафор по результатам
проверки значений, содержащихся в массиве val; каждый процессор в системе
управляет значением одного элемента массива. Прежде чем заблокировать семафор,
процессор проверяет, не заблокирован ли уже семафор другими процессорами
(соответствующие им элементы в массиве val тогда имеют значения, равные 2), а
также не предпринимаются ли попытки в данный момент заблокировать семафор со
стороны процессоров с более низким кодом идентификации (соответствующие им
элементы имеют значения, равные 1). Если любое из условий выполняется,
процессор переустанавливает значение своего элемента в 1 и повторяет попытку.
Когда функция Pprim открывает внешний цикл, переменная цикла имеет значение, на
единицу превышающее код идентификации того процессора, который использовал
ресурс последним, тем самым гарантируется, что ни один из процессоров не может
монопольно завладеть. Функция Vprim освобождает семафор и открывает для других
процессоров возможность получения исключительного доступа к ресурсу путем
очистки соответствующего текущему процессору элемента в массиве val и
перенастройки значения lastid. Чтобы защитить ресурс, следует выполнить
следующий набор команд:
Pprim(семафор);
команды использования ресурса;
Vprim(семафор);
В большинстве машин имеется набор элементарных
(неделимых) инструкций, реализующих операцию блокирования более дешевыми
средствами, ибо циклы, входящие в функцию Pprim, работают медленно и снижают
производительность системы. Так, например, в машинах серии IBM 370
поддерживается инструкция compare and swap (сравнить и переставить), в машине
AT&T 3B20 - инструкция read and clear (прочитать и очистить). При
выполнении инструкции read and clear процессор считывает содержимое ячейки
памяти, очищает ее (сбрасывает в 0) и по результатам сравнения первоначального
содержимого с 0 устанавливает код завершения инструкции. Если ту же инструкцию
над той же ячейкой параллельно выполняет еще один процессор, один из двух
процессоров прочитает первоначальное содержимое, а другой - 0: неделимость
операции гарантируется аппаратным путем. Таким образом, за счет использования
данной инструкции функцию Pprim можно было бы реализовать менее сложными
средствами:
struct semaphore
{
int lock;
};
Init(semaphore)
struct semaphore semaphore;
{
semaphore.lock = 1;
}
Pprim(semaphore)
struct semaphore semaphore;
{
while (read_and_clear(semaphore.lock));
}
Vprim(semaphore)
struct semaphore semaphore;
{
semaphore.lock = 1;
}
Процесс повторяет инструкцию read and clear в
цикле до тех пор, пока не будет считано значение, отличное от нуля. Начальное
значение компоненты семафора, связанной с блокировкой, должно быть равно 1. Как
таковую, данную семафорную конструкцию нельзя реализовать в составе ядра
операционной системы, поскольку работающий с ней процесс не выходит из цикла,
пока не достигнет своей цели. Если семафор используется для блокирования
структуры данных, процесс, обнаружив семафор заблокированным, приостанавливает
свое выполнение, чтобы ядро имело возможность переключиться на контекст другого
процесса и выполнить другую полезную работу. С помощью функций Pprim и Vprim
можно реализовать более сложный набор семафорных операций, соответствующий тому
составу, который определен в разделе “Определение семафоров”. Для начала дадим
определение семафора как структуры, состоящей из поля блокировки (управляющего
доступом к семафору), значения семафора и очереди процессов, приостановленных
по семафору. Поле блокировки содержит информацию, открывающую во время
выполнения операций типа P и V доступ к другим полям структуры только одному
процессу. По завершении операции значение поля сбрасывается. Это значение
определяет, разрешен ли процессу доступ к критическому участку, защищаемому
семафором.
Алгоритм
операции P:
/*
Операция над семафором типа P
входная информация:
(1)
семафор;
(2)
приоритет;
выходная информация:
0 - в
случае нормального завершения;
1 - в случае аварийного выхода
из состояния приостанова по cигналу, принятому в режиме ядра;
*/
{
Pprim(semaphore.lock);
уменьшить
(semaphore.value);
если
(semaphore.value >= 0)
{
Vprim(semaphore.lock);
вернуть (0);
}
/* следует
перейти в состояние приостанова */
если
(проверяются сигналы)
{
если (имеется сигнал,
прерывающий нахождение в состоянии приостанова)
увеличить
(semaphore.value);
если (сигнал
принят в режиме ядра)
{
Vprim(semaphore.lock);
вернуть
(-1);
}
в
противном случае
{
Vprim(semaphore.lock);
longjmp;
}
}
}
поставить процесс в конец
списка приостановленных по семафору;
Vprim(semaphore.lock);
выполнить
переключение контекста;
проверить сигналы
(см. выше);
вернуть
(0);
}
В начале выполнения алгоритма операции P ядро с
помощью функции Pprim предоставляет процессу право исключительного доступа к
семафору и уменьшает значение семафора. Если семафор имеет неотрицательное
значение, текущий процесс получает доступ к критическому участку. По завершении
работы процесс сбрасывает блокировку семафора (с помощью функции Vprim),
открывая доступ к семафору для других процессов, и возвращает признак успешного
завершения. Если же в результате уменьшения значение семафора становится
отрицательным, ядро приостанавливает выполнение процесса, используя алгоритм,
подобный алгоритму sleep: основываясь на значении приоритета, ядро проверяет
поступившие сигналы, включает текущий процесс в список приостановленных
процессов, в котором последние представлены в порядке поступления, и выполняет
переключение контекста.
Алгоритм V
/*
Операция над семафором типа V
входная информация: адрес
семафора
выходная информация:
отсутствует
*/
{
Pprim(semaphore.lock);
увеличить (semaphore.value);
если
(semaphore.value <= 0)
{
удалить из списка процессов,
приостановленных по семафору, первый по счету процесс;
перевести
его в состояние готовности к запуску;
}
Vprim(semaphore.lock);
}
Операция V получает исключительный доступ к семафору
через функцию Pprim и увеличивает значение семафора. Если очередь
приостановленных по семафору процессов непустая, ядро выбирает из нее первый
процесс и переводит его в состояние "готовности к запуску". Операции
P и V по своему действию похожи на функции sleep и wakeup. Главное различие
между ними состоит в том, что семафор является структурой данных, тогда как
используемый функциями sleep и wakeup адрес представляет собой всего лишь
число. Если начальное значение семафора - нулевое, при выполнении операции P
над семафором процесс всегда приостанавливается, поэтому операция P может
заменять функцию sleep. Операция V, тем не менее, выводит из состояния
приостанова только один процесс, тогда как однопроцессорная функция wakeup
возобновляет все процессы, приостановленные по адресу, связанному с событием. С
точки зрения семантики использование функции wakeup означает: данное системное
условие более не удовлетворяется, следовательно, все приостановленные по
условию процессы должны выйти из состояния приостанова. Так, например,
процессы, приостановленные в связи с занятостью буфера, не должны дальше
пребывать в этом состоянии, если буфер больше не используется, поэтому они
возобновляются ядром. Еще один пример: если несколько процессов выводят данные
на терминал с помощью функции write, терминальный драйвер может перевести их в
состояние приостанова в связи с невозможностью обработки больших объемов
информации. Позже, когда драйвер будет готов к приему следующей порции данных,
он возобновит все приостановленные им процессы. Использование операций P и V в
тех случаях, когда устанавливающие блокировку процессы получают доступ к
ресурсу поочередно, а все остальные процессы - в порядке поступления запросов,
является более предпочтительным. В сравнении с однопроцессорной процедурой
блокирования (sleep-lock) данная схема обычно выигрывает, так как если при
наступлении события все процессы возобновляются, большинство из них может вновь
наткнуться на блокировку и снова перейти в состояние приостанова. С другой
стороны, в тех случаях, когда требуется вывести из состояния приостанова все
процессы одновременно, использование операций P и V представляет известную
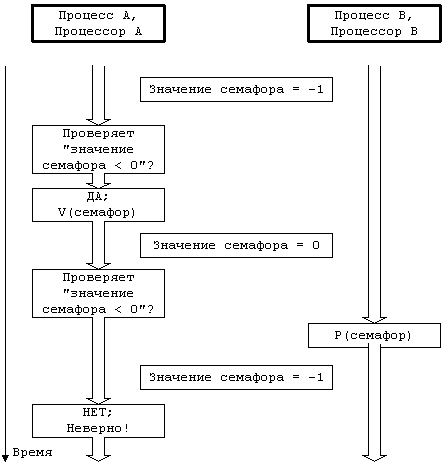
сложность. Если операция возвращает значение семафора, является ли она
эквивалентной функции wakeup?
while (value(semaphore)
< 0)
{
V(semaphore);
};
Если вмешательства со стороны других процессов
нет, ядро повторяет цикл до тех пор, пока значение семафора не станет больше
или равно 0, ибо это означает, что в состоянии приостанова по семафору нет
больше ни одного процесса. Тем не менее, нельзя исключить и такую возможность,
что сразу после того, как процесс A при тестировании семафора на одноименном
процессоре обнаружил нулевое значение семафора, процесс B на своем процессоре
выполняет операцию P, уменьшая значение семафора до –1.
|